OpenAI在2022年11月30日推出了ChatGPT,自首次发布以来,这种语言模型在互联网上引起了巨大的关注。然而,尽管不同行业和背景的互联网用户都在过度探索ChatGPT,但很少有人对其背后的技术、机制和潜力有充分的了解。
为了帮助圈友更好地了解ChatGPT,我从定义、主要应用和限制三个方面分享了我的收获。
ChatGPT是由OpenAI开发的大型语言模型(LLM),基于GPT-3(生成式预训练转换器)架构,专注于自然语言处理(NLP)。该模型在大量文本数据集上进行预训练,然后针对特定任务进行微调,以提供以下应用:语言翻译、文本摘要、代码调试和问答等。
由于ChatGPT是预训练的,因此它可以生成更自然、更流畅的文本,比仅针对特定任务进行微调的模型更为优秀。该语言模型具有很高的准确性,能够从对话的一端到另一端进行理解,并生成类似人类的答案。这意味着它可以理解和响应自然语言查询,并与人类一样有效地进行回应。
然而,尽管ChatGPT具有很高的效率和准确性,但它仍然存在一些限制。例如,由于它是通过预训练数据集训练的,因此它可能不能够适用于所有场景。此外,该模型可能存在偏见和不准确的结果,需要在使用前进行适当的检查和校正。
因此,要充分利用ChatGPT的潜力,需要仔细评估它的适用性和可靠性,并在必要时进行适当的调整和设置。在正确使用ChatGPT的前提下,它将成为一个极其有用的工具,可以帮助我们更好地处理自然语言处理任务。
一、ChatGPT 是如何训练的?
一、ChatGPT的训练方式
ChatGPT是基于GPT-3.5的,在Azure AI超级计算平台上进行了训练。在人类训练师的指导下,采用监督学习和强化学习方法对ChatGPT进行了修正和改进。训练过程包括三个步骤:
- 监督学习:首先,通过人类同时扮演用户和AI助手角色的对话示例来让模型进行学习。
- 强化学习:接着,人类训练师根据模型在先前对话中的反应评估模型,并利用这些反馈创建奖励模型。
- Proximal Policy Optimization (PPO):最后,通过多次迭代使用称为PPO的技术来进一步微调模型。
ChatGPT 的学习过程:
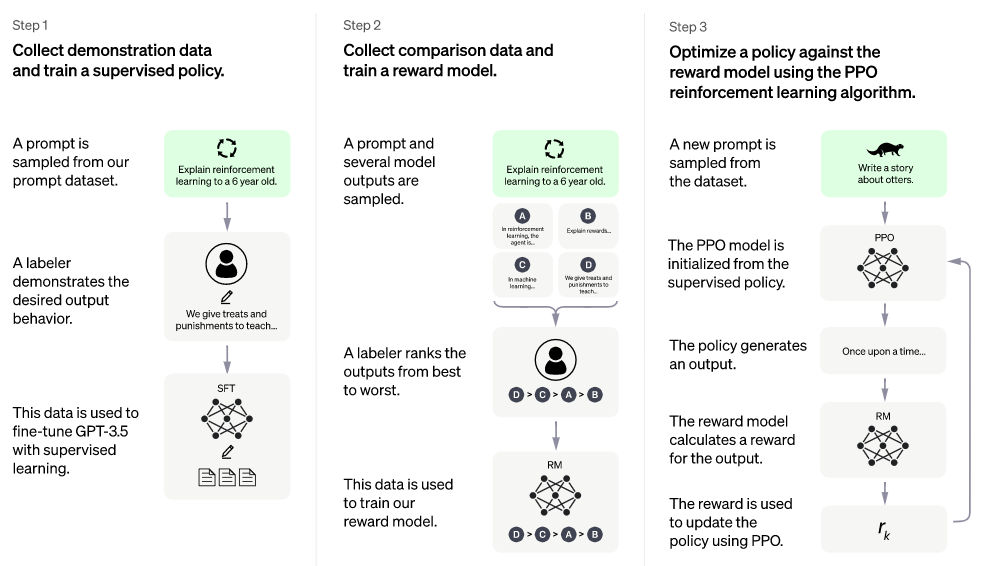
图片来源:OpenAI官网
二、ChatGPT 如何运作?
ChatGPT 通过使用预先训练的转换器神经网络架构生成文本。它在一个大型文本数据集(称为通用爬取数据集)上进行训练,从而学习人类书写文本的模式和结构。这个模型的目的是在给定已有单词的情况下预测句子中的下一个单词。
该模型包含一个编码器和一个解码器:
- 编码器:将输入文本转换为固定长度的向量表示,以捕获输入文本的意义。
- 解码器:使用此向量表示生成输出文本,一次生成一个单词。
在生成过程中,ChatGPT 使用注意力机制,它允许模型在预测时对不同部分的输入进行权衡。这有助于生成更连贯和适当的上下文的文本。
对于特定的任务,模型进一步在特定于该任务的较小数据集上进行微调。例如,如果任务是语言翻译,则模型将针对一种语言的文本数据集和另一种语言的翻译进行微调。这种微调过程允许模型学习任务特定的模式和结构,从而提高其在任务上的性能。
请注意,模型理解和响应用户输入的能力受到其训练数据和从该数据概括出的能力的限制。如果用户输入与模型看到的数据差异较大,它可能无法生成相关或准确的响应。
三、与 ChatGPT 交互的最佳方式是什么?
在与ChatGPT交互时,并不存在明确的正确或错误方法。然而,可以根据一些指南制定适当的询问方式。
ChatGPT不断发展,但是以下六种基本询问方式应该是不变的。
下面是我实际操作的几个操作ChatGPT的录屏:
请使用2倍速观看
1.ChatGPT生成一个 SVG 图标代码并将其复制并粘贴到figma图纸上
暂时无法在飞书文档外展示此内容
2.如何在小红书等平台火起来
暂时无法在飞书文档外展示此内容
3.让 ChatGPT 以表格格式生成响应,这样您就可以快速将信息复制并粘贴到任何其他电子表格
暂时无法在飞书文档外展示此内容
以下为粘贴复制出的表格:
方法描述内容发布高质量、有深度、有观点的问题和回答,让用户看到你的独特见解和专业知识。热门话题关注热门话题,及时参与讨论,可以让更多人注意到你。互动积极与其他用户互动,回复评论、点赞、分享,可以增加曝光率和影响力。社群加入和关注自己感兴趣的社群,参与讨论,可以扩大影响力。推广通过推广服务,将问题和回答推荐给更多用户,增加曝光和关注度。
所以要获得您想要的结果,您需要尽可能具体的文本提示
基础的提示守则:
- ChatGPT 已经用多种语言的数据进行了训练,但训练材料中的英文文本量要高得多。用英语运行查询,然后在使用翻译软件输出会很有帮助
- ChatGPT 在一次输入中最多处理 4,096 个标记,超出此范围的任何字符都将被忽略而不会显示消息。
- 如果您注意到 ChatGPT 的方向错误,可以使用输入字段上方的停止按钮停止响应生成
- 如果在聊天期间交换了太多知识,开始新的聊天可能会有所帮助,这样后续的回复就不会被破坏
- 尽管与 ChatGPT 聊天有时感觉几乎是人性化的,但不需要像“请”和“谢谢”这样的礼貌用语ChatGPT 不需要模糊的指令,只需要清晰的指令
四、定义 ChatGPT 的角色功能
ChatGPT 可以扮演我们社会中的绝大多数角色。人工智能所需要的只是朝着正确方向的推动。
1.语言翻译
ChatGPT 可以针对特定任务进行微调,例如语言翻译,它可以用于将一种语言翻译成另一种语言。该模型的翻译技巧和速度令人印象深刻。
2.内容生成
ChatGPT 可用于根据其从训练数据中学到的模式和关系生成新文本。这在以下应用中很有用:
- 内容创建,如文章
- 创意写作,如故事或诗歌
- 配方形成
- 作业准备等
3.关联性提问
我需要一个关于 ChatGPT 的机会和风险的短视频脚本。使用短句。直接向听众讲话,使用中性语言。
让 ChatGPT 做你想让它做的事的一个核心方面是“关联性提问”。这涉及将复杂的任务分解成几个中间步骤,希望 AI 能够生成更具体、定制化并因此总体上更好的结果。这适用于单个长提示以及连续的多个提示。
可能最简单的关联提示形式是,首先询问文章的结构。然后你可以告诉 ChatGPT 制定相应的要点。
这种方法还可以节省时间:如果您注意到 AI 在大纲期间走错了路,您可以在生成全文之前进行必要的调整。
4.修改输出
您可能准备相同的内容,想分发到不同的平台,例如 小红书、微博或知乎,匹配不同平台的内容形式。同样,ChatGPT 会在正确的提示下处理此任务。
5.代码调试
ChatGPT 可以通过几种不同的方式用于代码调试:
通过提供有关错误和预期结果的上下文来生成代码建议或修复代码错误
对代码进行自然语言解释,可以帮助开发人员理解代码的工作原理并识别错误
创建测试用例,这有助于识别可能不会立即显现的错误
五、ChatGPT 的局限性
1.有偏见的反应和有害的指示
ChatGPT 是通过在大型文本数据集上进行训练而生成的,其中可能包含偏见,就像人类也有偏见一样。这可能导致模型产生有偏见的反应,特别是在敏感话题,如性别、种族和性取向方面。
OpenAI 表示,他们已采取措施来防止模型产生不适当的响应,但模型有时仍可能产生有害的响应。为了解决这个问题,他们正在使用 Moderation API 来标记和防止某些类型的不安全内容。OpenAI 还依赖用户反馈来改进模型,并通过允许用户评估响应来收集用户反馈。
2.过时的知识库
由于 ChatGPT 是在 2021 年之前的特定数据集上训练的,因此它只能根据从该数据集中学到的知识回答问题。如果该数据集已经过时,那么模型的回答可能不准确或与当前时间不相关。此外,模型可能无法理解或回答在数据集创建后出现的新概念、技术或信息。
3.网络和容量问题
通常在生成长文本时,ChatGPT 会遇到网络错误,聊天机器人需要 60 多秒才能返回答案。另外,由于需求量巨大,有时它会超出一些用户的容量限制。
4.短语过度使用
ChatGPT 模型生成的重复的响应有时过多,包括反复声明它是由 OpenAI 训练的语言模型。这是由于训练数据中的偏差引起的,正如 OpenAI 所宣称的。
5.偶尔生成不正确的答案
有时,ChatGPT 可能生成听起来合理但实际不正确或荒谬的答案。比如,对于用户关于事实的查询,ChatGPT 的答案可能是不正确的。
ChatGPT 不会访问互联网来寻找答案,它仅通过根据其训练,选择最可能跟随的“标记”,以此来构建句子。这意味着,ChatGPT 通过做出一系列假设来生成答案,但这些假设可能导致提供错误的答案。
由于这个问题,经常被程序员和开发人员使用的 Stack Overflow 网站暂时禁止其用户分享 ChatGPT 生成的答案。
OpenAI 意识到了 ChatGPT 的这一局限性,它并不能正确回答,并指出由于聊天机器人的训练方法,解决这个问题并不容易。
以上内容大部分参考自 OpenAI 官方公示。