ЧоҪьС§П°ҙуАР№ШУЪAIЙн·ЭЙи¶ЁөДҝОіМЧЬҪбЈә
өЪТ»ХРЎўAIЙн·ЭИзәОЙи¶ЁЈҝ
ОТГЗ¶јЦӘөАЈ¬ёъGPT¶Ф»°өДКұәтЈ¬ТӘёшTAЙи¶ЁЙн·ЭЈ¬TAКЗЛӯЈ¬НЁіЈіЖОӘcosplayөДҪЗЙ«°зСЭЎЈ
ДЗГҙЙн·ЭёГФхГҙЙи¶ЁЈҝУРДДР©Йн·ЭАаРНТӘЗеіюЈ¬ЦчТӘУРТФПВ4ҙуАаЙн·ЭЈә
1ЎўјјКхЙн·ЭЎӘЎӘЦ°ТөјјДЬИЛФұЈ»
2ЎўЙъ»оЙн·ЭЎӘЎӘЕуУСЎўБЪҫУЎўҙуТҜҙуВиЈ»
3Ўў№ӨЧчЙн·ЭЎӘЎӘН¬КВЎўАП°еЎўПВКфЈ»
4ЎўјТНҘЙн·ЭЎӘЎӘ°ЦВиЎўХЙ·тЎўЖЮЧУЎў¶щЕ®Ј»
ТФЙПХвР©Йн·ЭКЗДгЙи¶ЁёшGPTөДЈ¬Н¬КұGPTТІРиТӘЦӘөАДгөДЙн·ЭЈ¬ХвҪРЦӘұЛЦӘјәЎў°ЩХҪІ»ҙщЎЈ
ДЗФхГҙФЛУӘХвР©Йн·ЭАаРНДШЈҝЙн·Э4ОКЈә
1ЎўЛӯ»бәНДг·ЦПнХв¶ООДЧЦЈҝ
2ЎўОДЧЦТӘёшЛӯҝҙЈҝ
3ЎўДгКЗЛӯЈҝ
4ЎўGPTКЗЛӯЈҝ
УГІ»Н¬АаРНөДЙн·ЭФЛУӘФЪМбОКЦРЈ¬Ў°ЦӘјәЦӘұЛЎұЈ¬·ҪДЬөГөҪёьУЕЦКөДҙр°ёЎЈ
°ёАэЛөГчЈәДгјЩПлёъДг¶Ф»°өДИЛ№ӨЦЗДЬЈ¬TAКЗТ»ёцВЙКҰЈ¬ДгҫН°СЙн·ЭЙи¶ЁёшTAЎЈ
ПЦФЪДгКЗТ»ГыЧЁТөөДВЙКҰЈ¬РиТӘДг°пОТРҙТ»·ЭРӨПсК№УГИЁКЪИЁРӯТйЈЁ»тХЯұЈГЬРӯТйөИЈ©Ј¬јЧ·ҪКЗЈәХЕИэЈ¬ТТ·ҪКЗЈәАоЛДЎЈ
ұИИзДгКЗТ»ёцЕ®Ч°НшөкөДАП°еЈ¬ДгТІПлУГИЛ№ӨЦЗДЬИҘМбёЯДгөДР§ВКЈ¬ХвЦРјдЧоЦШТӘөДТ»»·Ј¬ИзәОЕаСөәГДгөДПЯЙПҝН·юЈ¬Хвёц№ӨЧчНкИ«ҝЙТФҪ»ёшИЛ№ӨЦЗДЬАҙЧцЎЈ
јЩЙиДгПЦФЪКЗҝӘЕ®Ч°НшөкөДҝН·юЈ¬ОТКЗ№ЛҝНЈ¬ДгАҙ»ШҙрОТөДКЫәуОКМвЈ¬ҝЙТФВрЈҝ
ОТКЗТ»ёцЕЦЕ®ИЛЈ¬ұИҪПГ»УРЧФРЕЈ¬ДгГЗөкөДТВ·юККәПОТВрЈҝөИөИҫНҝЙТФДЈ·ВХжКөҝН»§ёъAI¶Ф»°БЛЎЈ
өЪ¶юХРЎўУЕ»ҜЙн·ЭИЛОпDNAЎЈ
ОӘКІГҙДгЧЬКЗТӘУЕ»ҜРЎGКдіцөДОДұҫЈҝКЗТтОӘДгГ»УРёшЛыЗеОъөДБЛҪвИЛОпөДDNAЎЈ
ұИИзИГGPTКдіцТ»ЖӘРЎәмКйұКјЗЈ¬ОТГЗРиТӘЦЦІЭөДёРҫхЈ¬ёшҪгГГ·ЦПнөДөчөчЎЈ
ИэЧйОКМвЈә
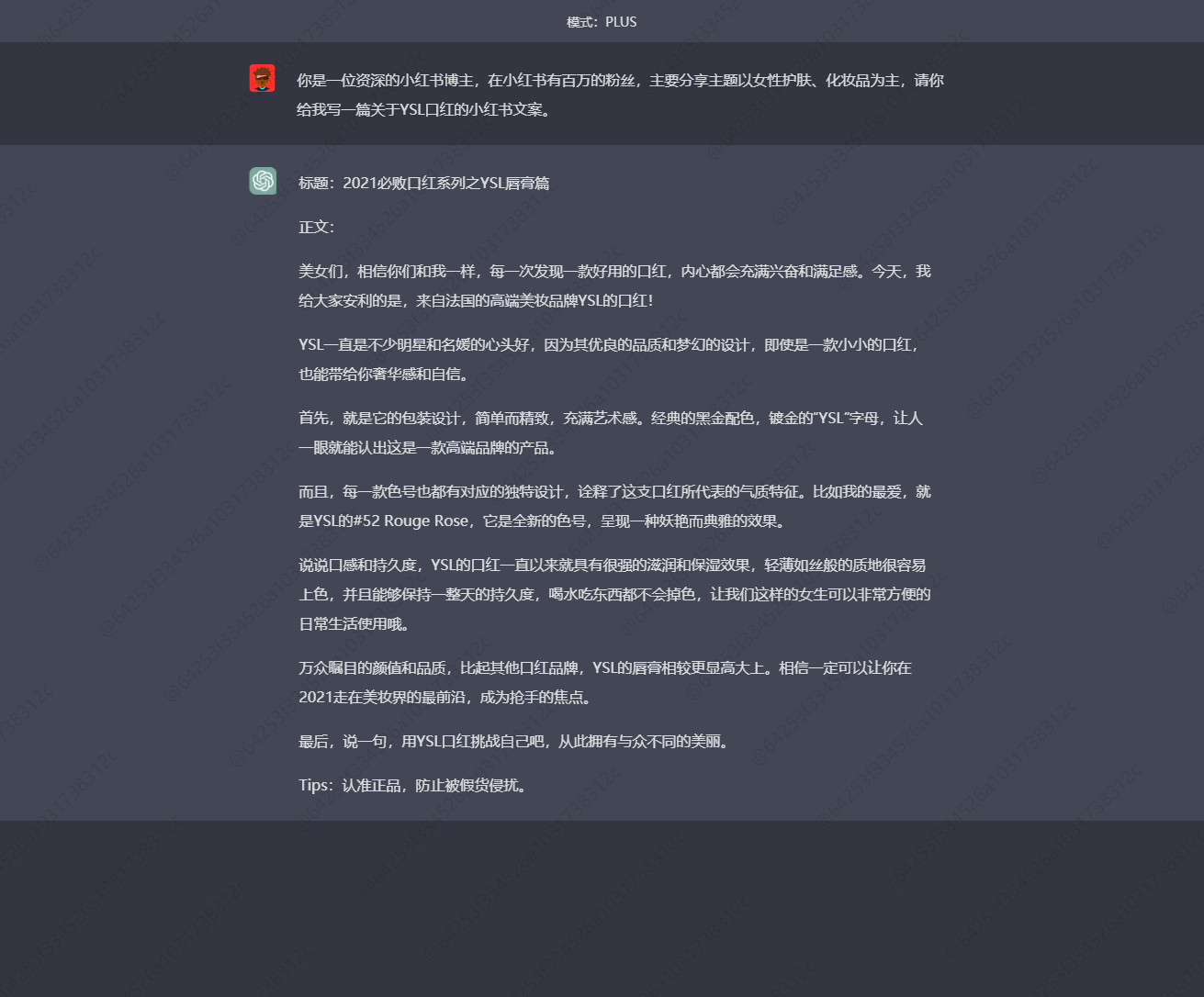
1ЎўРҙТ»ЖӘ№ШУЪYSLҝЪәмөДРЎәмКйұКјЗ
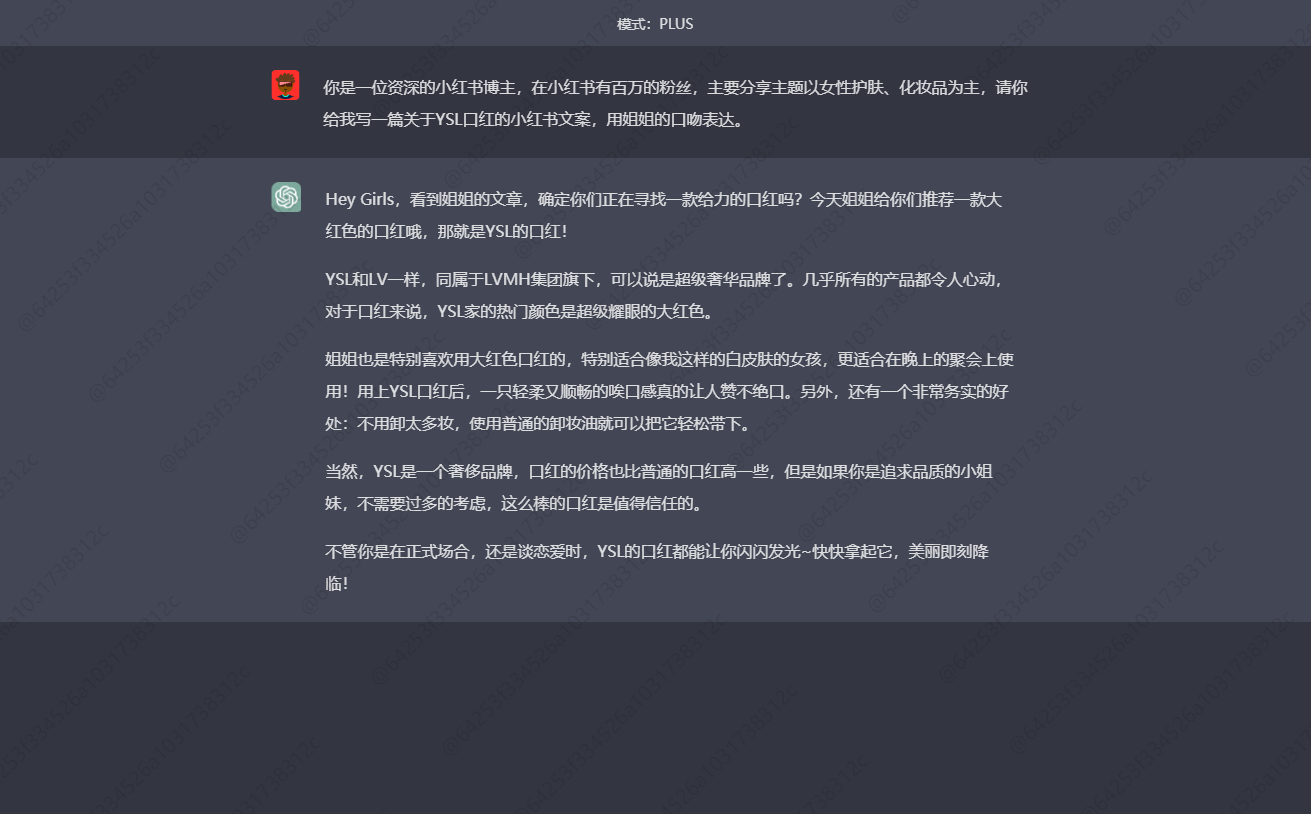
2ЎўРҙТ»ЖӘ№ШУЪYSLҝЪәмөДРЎәмКйұКјЗЈ¬УГҪгҪгөДҝЪОЗұнҙп
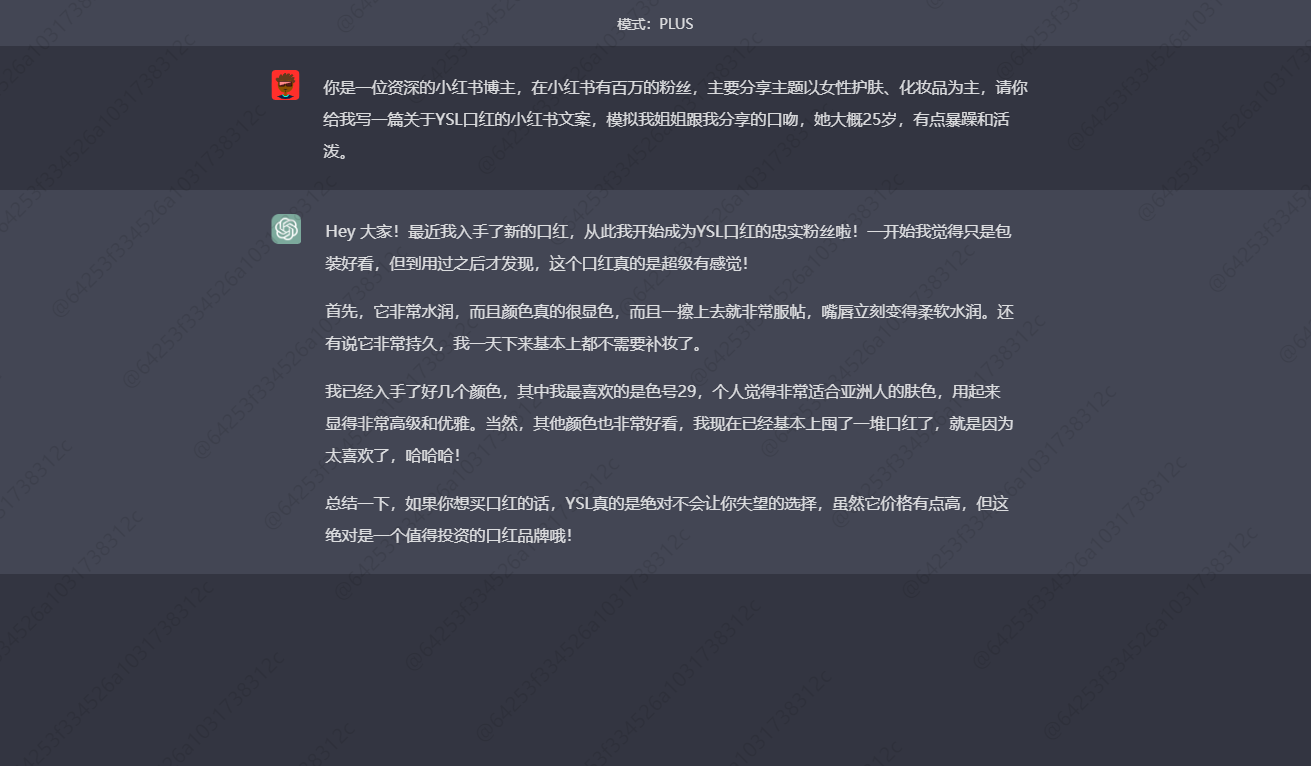
3ЎўРҙТ»ЖӘ№ШУЪYSLҝЪәмөДРЎәмКйұКјЗЈ¬ДЈДвОТҪгҪгёъОТ·ЦПнөДҝЪОЗЈ¬ЛэҙуёЕ25ЛкЈ¬УРөгұ©ФкәН»оЖГ
ТФЙПИэЧйОКМвЈ¬ОТ¶јёҪФЪТФПВНјЖ¬ЦРБЛЈ¬ЗлІйҝҙЈә
іцАҙөДҪб№ыәЬГчПФЈ¬
өЪТ»ЖӘКЗПкЗйТіөДёРҫхЈ»
өЪ¶юЖӘКЗ№гёжҪйЙЬЈ¬УРПъКЫО¶Ј»
өЪИэЖӘҫНКЗТ»ЖӘҪ»БчёРЕЁәсЎўЗТёцРФПКГчөДЦЦІЭұКјЗЈЎ
ДгЦ»ТӘЙФјУұнЗйҫНДЬ·ўІјБЛЈ¬КЗІ»КЗәЬФЮЈҝТ»ІҪөҪО»ёг¶ЁРЎәмКйІ©ОДЈ¬Л¬І»Л¬Јҝ
ЛщТФЈ¬ФЪМбОКөДКұәтЈ¬ө«·ІЙжј°өҪДіёцЙн·ЭИЛОпКұәтЈ¬ТӘҫЎҝЙДЬИҘУЕ»ҜЛьөДDNAЎЈ
ҝЙТФҙУХв5ёцҪЗ¶ИИлКЦЈә
1ЎўіЎҫ°
2ЎўЙн·Э
3ЎўДкБд
4ЎўРФёс
5ЎўУпЖш
өЪИэХРЈәМбОКВЯјӯЈ¬әЛРДКцЗу+ФӘЛШІрҪв
өЪТ»Ўў°СәЛРДЛЯЗуёжЛЯGPTЎЈ
ТтОӘОТГЗИЛРФУРёцНЁІЎЈәФЪұнҙпЧФјәУыНыөДКұәтЈ¬»бПИЛөұнГжөДРиЗу»тОКМвЈ¬¶ш·ЗәЛРДЛЯЗуЎЈ
ұИИзАПЖЕұ§Ф№ДгЦ»№ШРД№ӨЧчЈ¬ГҝМмәЬНн»ШјТЈ¬ХвКЗұнГжРиЗуЈ¬ПлИГДг¶аЕгЛэІЕКЗәЛРДРиЗуЈ»ПлС§әГК№УГchatGPTКЗұнГжРиЗ󣬻сИЎР§ВКМбЙэЈ¬НЁ№эgptұдПЦІЕКЗәЛРДКцЗуЎЈ
ЛщТФМбОКВЯјӯөЪТ»ТӘЛШЈә°СәЛРДЛЯЗуёжЛЯGPTЈә
ДгКЗКІГҙИЛЈҝПлЧцКІГҙКВЈҝҙпөҪКІГҙДҝөДЈҝНЁ№эКІГҙСщөД·Ҫ·ЁҙпіЙЈҝЖЪНыУРКІГҙСщөДҪб№ыЈҝ
ЮрЖъЧФјәЖҪКұөДұнГжОКМвЈ¬ІЕУРҝЙДЬөГөҪёьәГөДҙр°ёЎЈ
ПЦФЪС§»бБЛФхГҙМбОКЈ¬КЗІ»КЗҫНҝЙТФТ»ІҪөҪО»ДШЈҝNoЎ«ҪвҙрОКМвGPT»№РиТӘЧг№»өДПЯЛчЎЈ
өЪ¶юЎўТӘІрҪвВЯјӯЎЈ
ІрҪвВЯјӯЈ¬ҫНКЗ°СДгөДОКМвЦРЙжј°өДФӘЛШ·ЦІрҝӘАҙЈ¬МШұрКЗЙЩјыөДҙК»гРЕПўЈ¬ПИёшGPTИИЙнјмЛчЈ¬И·ұЈЛьАнҪвөДТвЛјәНДгТӘөДТ»ЦВЈ¬ДгГЗБ©өДРЕПў¶ФіЖБЛЈ¬ҙр°ёІЕ»бёьјУЧјИ·ЎЈ
ҫЩАэЈәЗлЧчОӘҙҙТөХЯЈ¬РҙТ»·ЭКУЖөәЕ№ШУЪІиЕ©ҙш»хөДЙМТөјЖ»®КйЈ¬УГУЪВ·СЭЎЈ
РЕПўІр·ЦЈә1Ўў КУЖөәЕЈ» 2ЎўІиЕ©ҙш»хЈ»3ЎўЙМТөјЖ»®КйЈ» 4ЎўВ·СЭЎЈ
ЖдЦРЎ°В·СЭЎұФЪІ»Н¬РРТөөДТвЛјІ»Н¬Ј¬ЛщТФДгРиТӘМбЗ°әНGPTИ·ИПКЗДгТӘөДҪв¶БЎЈ
ТтҙЛМбОКВЯјӯБҪҙуТӘЛШЈәәЛРДЛЯЗу әН ФӘЛШІрҪвЎЈ
өЪЛДХРЈәҪЁТй»эј«ЎўАсГІКдИлЎЈ
ёъGPT№өНЁөДКұәтЈ¬·ЕЛЙРДЗйЈ¬ПсёъТ»ёцЦӘРДЕуУСБДМмДЗСщИҘ¶ФҙэЎЈ
өұДгәНИЛ№ӨЦЗДЬ¶Ф»°КұЈ¬·ЗіЈҪЁТйДгАсГІТ»Р©ЎўОВИбТ»Р©Ј¬УГҙКІ»ТӘМ«№эУЪөНЛЧЎЈ
ОӘКІГҙДШЈҝТтОӘА¬»шКдИлЈ¬А¬»шКдіцЎЈ
ТтОӘДгОКМвЛщУГөДУпБПҝвЈ¬Ль»бЦұҪУУ°ПмДгәуРшҙУAIДЗұЯөчИЎөДЛШІДҝвЈ¬Из№ыДгУГҙКІ»өұЈ¬А¬»шКдИлЈ¬ДЗәуГжУГөҪөДЛШІДҝЙДЬТІІ»КЗДгТӘөДЈ¬НііЖОӘөНЦКЛШІДЎЈ
өЪОеХРЈәУГәГGPTөДНтДЬ·Ҫ·ЁВЫ
ҫӯ№эЗ°јёХРЈ¬ҫНҝЙТФМЦВЫ№«КҪАпЈ¬Бй»оФЛУГБЛЈЎ
step1ЈәГчИ·ЧФјәөДәЛРДЛЯЗуЈЁҫ«ЧјДҝөДЈ©
step2ЈәЙи¶ЁЙн·ЭЈЁМбОКХЯ/GPT/КдіцХЯ/КЬЦЪЈ©
step3ЈәІрҪвФӘЛШЈЁЛш¶ЁРЕПўҝвЈ©
step4Јә·бё»Йн·ЭөДDNA »тХЯДіёцРЕПўөгөДЙо¶ИЈЁУЕ»Ҝҙр°ёЈ¬УГҙК»эј«АсГІЈ©
»щУЪТФЙП5ІҪЈ¬АнВЫЙПДЬВъЧгДгМбОКөД90%ТӘЗуЈ¬И»әуФЩОўөчІ№ідјҙҝЙЎЈИз№ы»№І»К®·ЦЖхәПЈ¬ДЗҫНРиТӘУГО№СшКэҫЭөД·ҪКҪИҘСөБ·Ј¬ХвАпОТ»№РиТӘПтҙуАРГЗјМРшС§П°Ј¬әуРшФЩ·ЦПнЎЈ
ҙуАР»№·ЦПнБЛФЪЛјО¬ДЈРНЙПЈ¬УРТ»ёцјјЗЙҫНКЗЙн·Э»Ҙ»»Ј¬Ў°GPTЈ¬Из№ыДгКЗОТөД»°»бФхГҙЧцЈҝЎұЎЈ